
Fun with C++ and cache lines
Estimating size of cache line using C++

I was recently watching Timur Doumler's CppCon video on writing fast C++ in which I came across an interesting concept related to cache lines called false sharing. This led to me to experiment with caching in my PC and programmatically estimate the cache line size. Before I dive into the technique, some background on caching and cache lines:
Modern systems make use of multi-level caching for faster memory access. There are usually three layers of caches - L1, L2, and L3. Each cache is exponentially larger than the other (L3 > L2 > L1) which leads to exponentially larger memory access time. On most systems, each core has its own L1 data and L1 instruction cache. Some systems like the one below may have an L2 cache per processor, while an L3 cache is almost always shared amongst the cores.

Whenever a memory address is requested, the CPU checks the L1 cache first. If the data is found, it uses that (ignoring modification by other threads for now). If the data is not found, it looks for it in the deeper caches and eventually in the main memory. The CPU then copies over the data to L1 cache. Interestingly, CPU usually just does not copy the data requested, but instead copies the nearby data as well expecting the user to request that data in future. This is called spatial locality. The principle of spatial locality says that if a program accesses one memory address, there is a good chance that it will also access other nearby addresses. Consider iterating through an array of size 8 - if the CPU has to access memory for each index 0 to 7, it would take much longer than copying the whole array in the L1 cache on access to index 0 and then simply reading from L1 cache.
To achieve spatial locality, cache is organized in chunks of memory called 'cache line'. Common cache line sizes include 32, 64, and 128 bytes. If you have an array of chars (size of char is usually 1 byte), a 64 byte cache line would imply that on accessing the first index of the array, the CPU would copy over the first 64 elements (64 bytes) into the cache. This implies that the access to the next 63 elements would be much faster. This is the core idea behind spatial locality.

Impact of cache line on performance
Cache lines can have some unintended effects. Consider the following example from Timur's talk where four threads are accessing four different variables. Note that none of the threads is mutating the same data.

Assume this program takes 4ms on a single core system. When the threads truly run in parallel on a four physical core system, it should roughly take 1/4th the time, ie around 1ms. Surprisingly, and quite unintuitively, this program runs significantly slower on a four core system. This is due to false sharing. The variables a, b, c, d are each 4 bytes (usually) and lie adjacent in the memory. Assuming a cache line size of 64 bytes, whenever thread t1 accesses 'a', it is going to fetch the memory around it including variables b, c, d and store it in its L1 cache. When thread t2 accesses b, it stores the same memory in its cache line and updates b. The updation of b leads to thread t1's cache line being invalidated as the 'b' stored in the cache line is now stale. This leads to thread t1 re-accessing memory. This occurs on each thread's data access and leads to worse performance on a multi core system. For detailed explanation, I would highly recommend watching Timur's talk.
Estimating size of cache line using C++
Some operating systems provide information for the cache line size. I am using Mac M4 which does not seem to expose this info. We can exploit properties of spatial locality and array access to estimate the size of cache line in the system. Note that sequential array access is fast due to chunk of memory being copied in the L1 cache which is immediately accessed in the next iteration. What happens if you iterate over the array in larger steps, accessing every n-th element?
Consider accessing every 2nd element vs accessing every 16th element of an array of bytes with 128 elements. In the former, we access 64 elements and in the latter, we access 8 elements. The time taken to iterate over the array with step size 2 must be much more than the step size 16. Well, it depends. The time taken is not bound by the number of elements accessed but rather by the main memory access. If the cache line size is 128, there is only a single main memory access (note the difference between cache access and main memory access) which leads to similar time taken. If the cache line size is 8 bytes, iteration with step size 2 still accesses all cache lines but an iteration with step size 16 only copies over half the cache lines. Hence, a step size lower than the size of cache line should lead to similar iteration time while any step size high than the size of cache line should lead to decreasing times (copying over less cache lines and iterating over less elements).
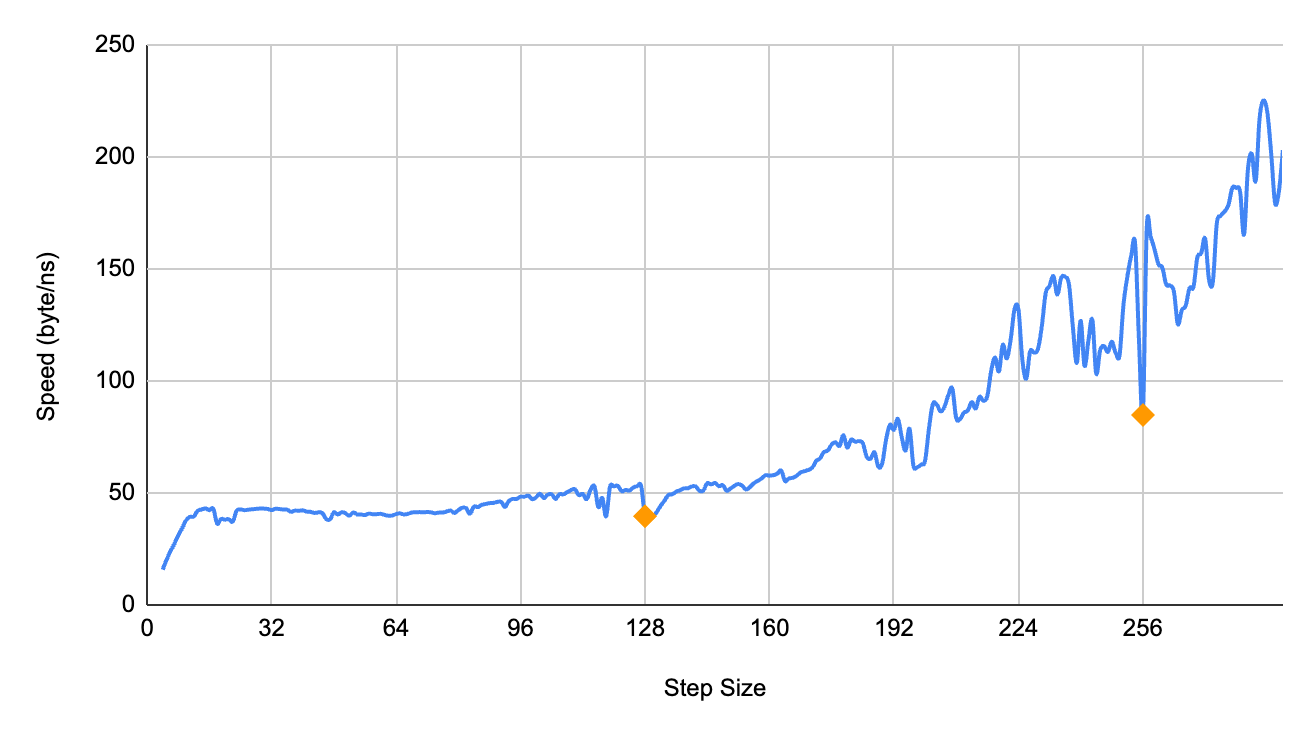
To estimate the cache line size, I iterated over a large array with step sizes from 2 to 290, and copy the element at each step into another array. I measure the average CPU time taken for the iteration and plot the speed of iteration (array size / avg time). As seen in the graph below, when step size is below 128 bytes, the speed of iteration is fairly similar. Over 128 bytes, the speed increases. This suggests that my machine has a 128 bytes cache line size. There is a significant difference in the speed at step size 128 and 256 - my guess is that this is because of the hardware prefetcher having a performance hit.
Code on GitHub: https://github.com/sarthak-sehgal/cpp-fun/tree/main/cache_line