
SPSC Queue Part 1: Ditch the Lock, Speed the Queue!
Comparing locking and lockless single producer, single consumer (SPSC) queue

Efficient inter-thread communication is a crucial aspect of high-performance systems, particularly in low-latency environments such as trading systems. One of the most fundamental and widely used concurrency primitives for such communication is the single producer single consumer (SPSC) queue. Despite its simplicity, the design choices made when implementing an SPSC queue can have a profound impact on performance, particularly in terms of latency.
In this article, I compare various implementations of a bounded SPSC queue (also known as a ring buffer), with a primary focus on latency characteristics. This serves as an introduction to lockless queue techniques. If you're already familiar with std::atomic, I recommend checking out Part 2 (coming soon), where I optimize and benchmark a lockless queue against boost::lockfree::spsc_queue.
Instead of discussing general-purpose implementations, I will analyze queues specifically designed for a high-performance environment, where the producer and consumer run on separate physical cores, continuously spinning while waiting for data. This setup eliminates context-switching overhead and ensures that performance differences stem from the queue's design rather than OS-level scheduling artifacts.
API and Benchmark Setup
Before diving into different implementations, let's define the requirements for the queue and the benchmarking methodology:
Singe Producer, Single Consumer: The queue will have exactly one producer and one consumer, simplifying the synchronization model.
Bounded Capacity: The queue has a fixed buffer size passed during construction.
Core Affinity & Spinning: Producer and consumer threads are pinned to separate physical cores and continuously poll for data.
API: The queue should be generic. It is passed the capacity during construction and implements two methods: bool push(const T&) and bool consume_one(auto&& func). push adds the element of type T if there is space, otherwise returns false. consume_one calls func with the element if the queue is non-empty, otherwise returns false.
Profiling: The performance will be tested with 1 million integers, using a buffer size of 1,000.
SPSC Queue v1: Good ol’ mutex
A simple way to implement a bounded queue is to store the data in a vector, and use mutex for synchronized access to the shared data. The implementation below uses ‘head’ and ‘tail’ indices to point to the position in the vector to be pushed to or consumed from. Since the queue is bounded by a given capacity, the vector can be resized on construction and we can avoid allocations during push and consume.
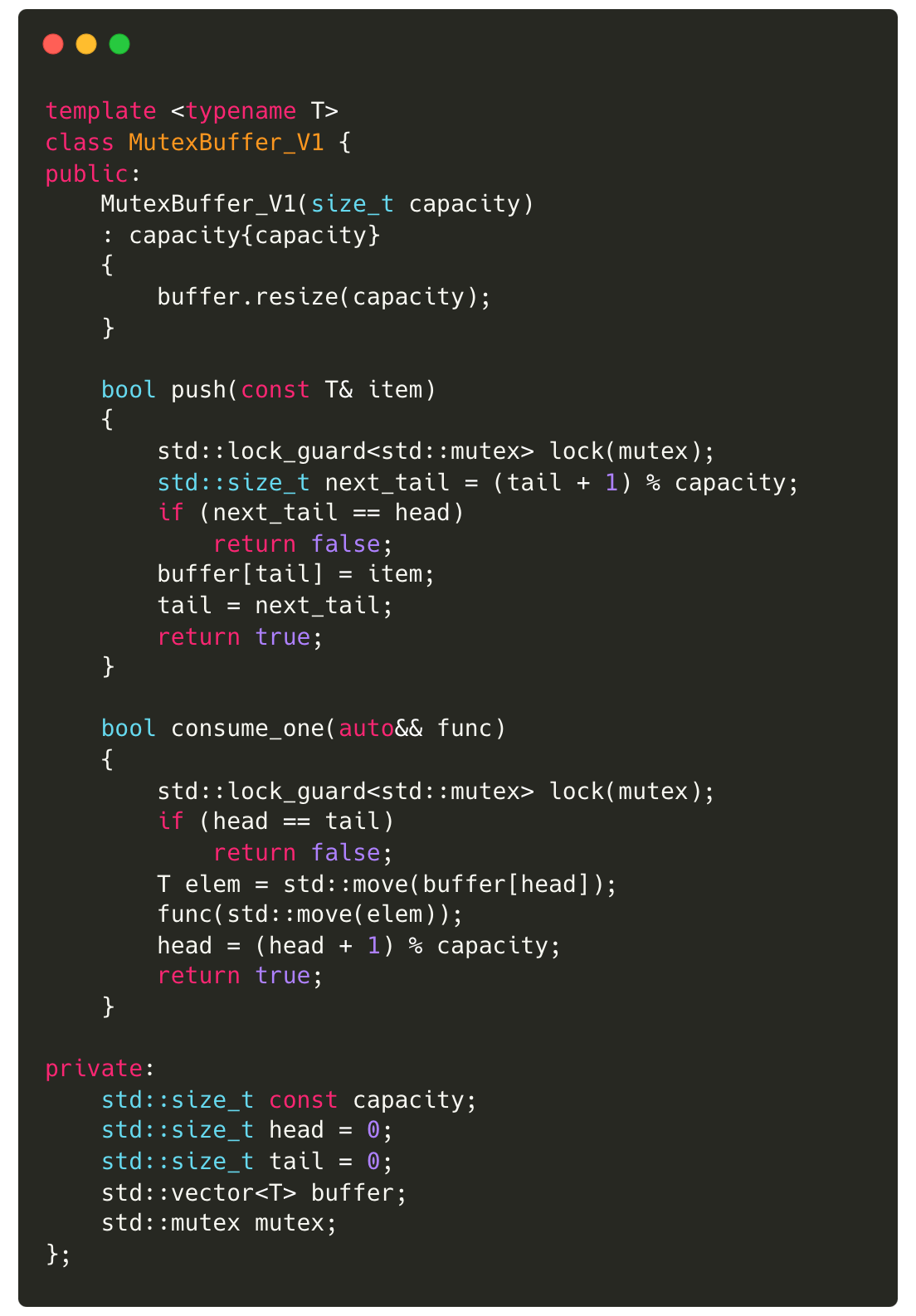
This queue works pretty well for most systems, but it has a few limitations:
The type T must be default-constructible.
Only one of the producer or consumer threads can run at a time. Since both threads attempt to acquire the lock, only one executes the code at any given moment. This deviates significantly from true parallelism and negatively impacts performance.
push() and consume_one() may block if the lock is held by the other thread. Given that our application uses pinned threads that continuously poll (spinning), a non-blocking design would be more suitable (read more).
SPSC Queue v1.1: Byte storage
Instead of using a vector to store the elements, can allocate a byte array of the required size, effectively creating a memory pool. Using placement new, we can construct objects of type T at the appropriate locations within this storage.
To implement this, we define an Element class that contains a byte array large enough to hold an instance of T. We then allocate an array of these Element objects at runtime (the `buffer`). New elements are constructed in place at buffer[tail], and when an element is consumed, it is explicitly destroyed to ensure proper cleanup. I have used std::construct_at and std::destroy_at for placement new/delete.
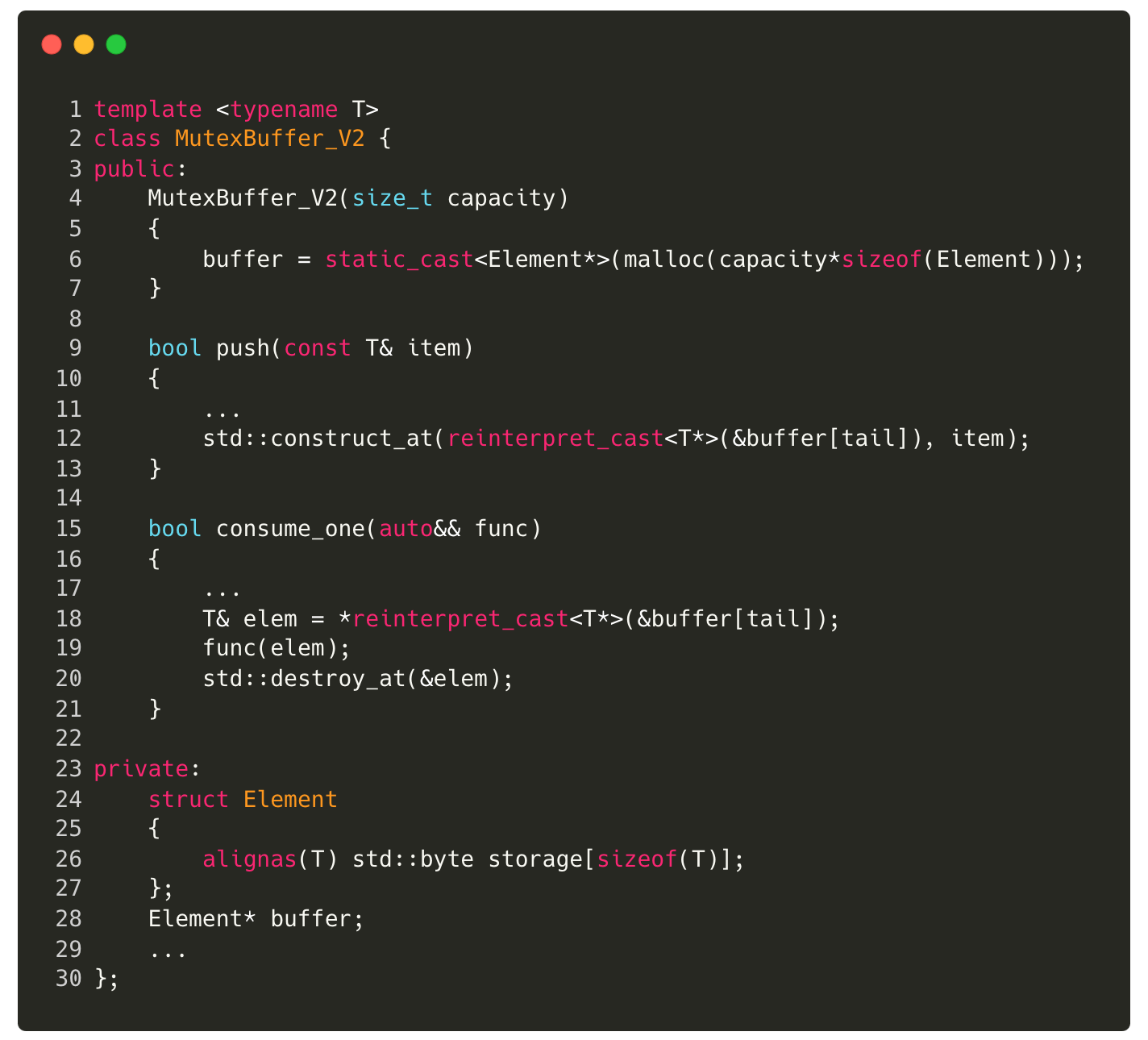
In the implementation above, notice the alignment on line 26. This is critical when working with a memory pool because the default alignment of byte storage is 1. However, the storage must be aligned to match T’s alignment requirements to construct elements of type T.
By using byte storage, we have eliminated the first limitation — T no longer needs to be default-constructible. However, it still must be copy-constructible due to the std::construct_at call. We haven’t done much about the second and the third limitations. Notice that the producer and consumer access different parts of the buffer: the producer always modifies the buffer’s tail, while the consumer works with the head. This means both threads can access the buffer simultaneously, requiring a lock only when accessing the head and tail.
To mitigate the second limitation, we can release the lock after performing the full/empty check, process the element without holding the lock, and then reacquire it to update the head/tail. While this theoretically allows more parallel execution, it incurs the overhead of locking and unlocking twice. In my benchmarks, this approach resulted in worse performance due to mutex locking being a significant source of latency. However, it may perform better in scenarios where the consumer’s callback function is nontrivial and time-consuming.
The third limitation cannot be resolved with mutexes alone. To achieve a non-blocking design, we need alternative synchronization mechanisms — this is where std::atomic comes in. Introduced in C++11, std::atomic provides lock-free atomic variables, ensuring that no other thread observes an intermediate state. If you're unfamiliar with std::atomic, I highly recommend watching Fedor Pikus’ talk from CppCon.
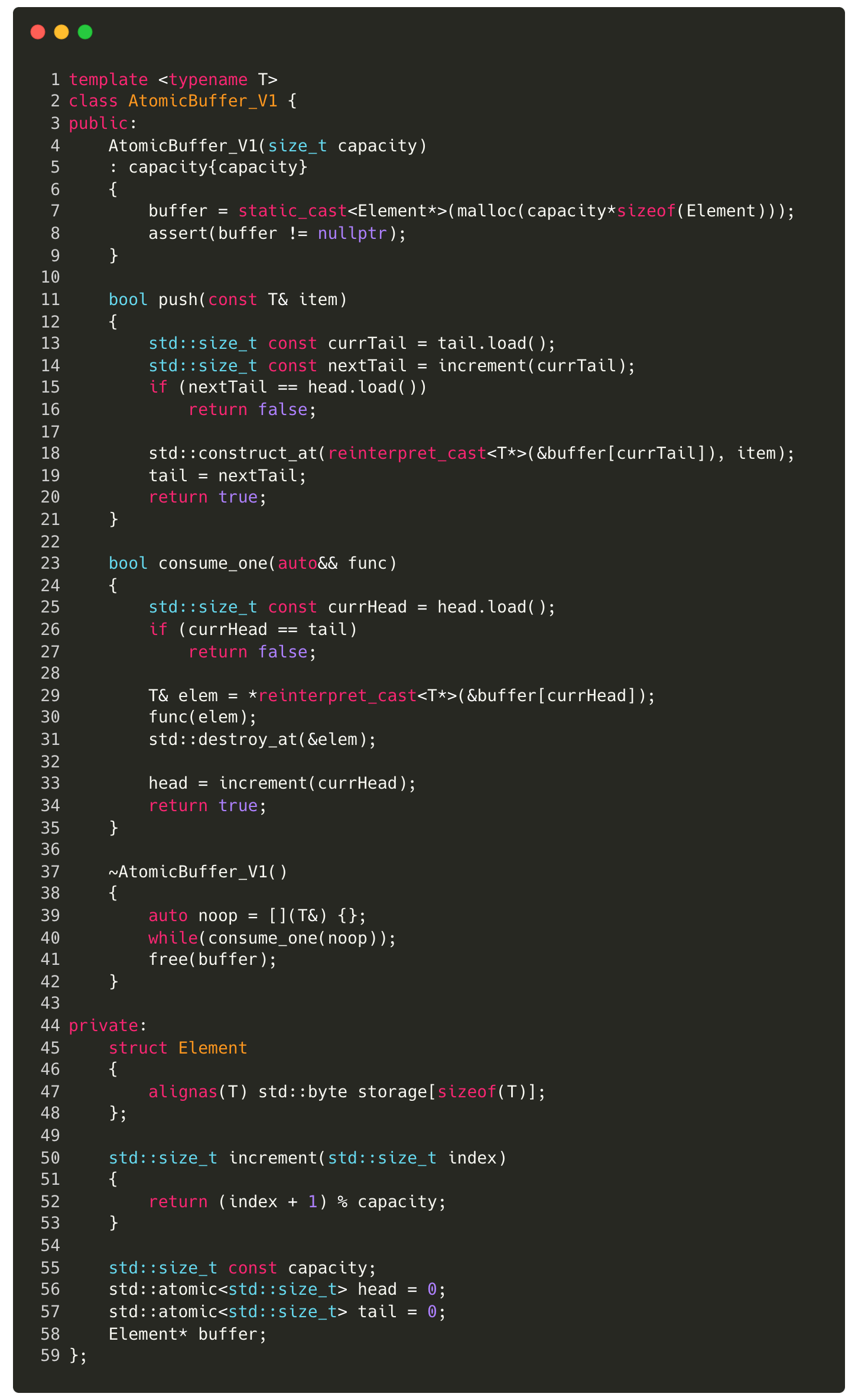
SPSC Queue v2: std::atomic
Atomic operations eliminate the need for locks by relying on compare and swap, and busy waiting rather than suspending thread execution. In contrast, a mutex enforces locking, which introduces the overhead of context switching. Given that both threads are actively spinning, suspending execution is unnecessary. Below is an implementation using std::atomic:
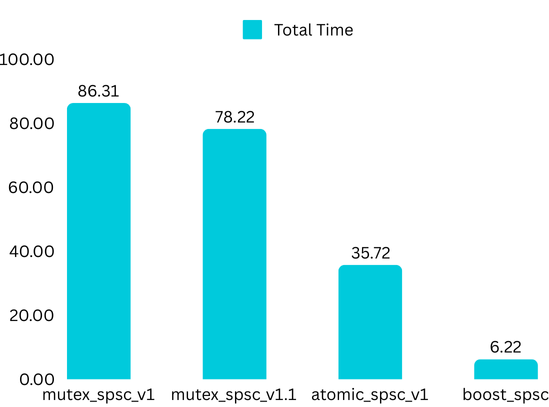
Profiling Results
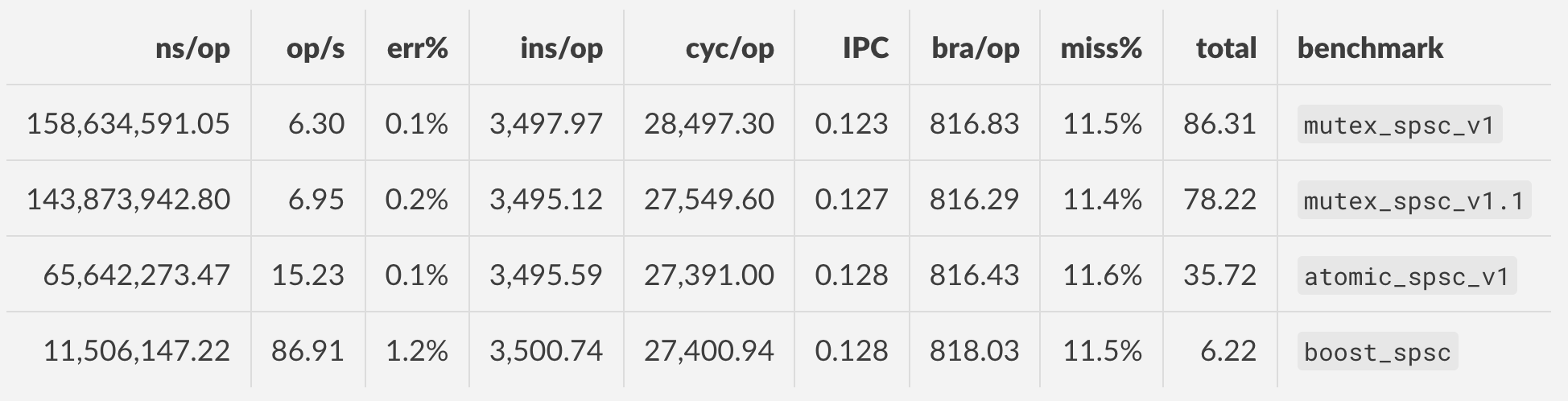
I used nanobench to profile different implementations, running each one 5 times with 100 iterations per run. The code can be found on GitHub.
As evident from the results below, the atomic SPSC bounded queue is more than 2 times faster than the mutex implementation. Further, I benchmarked the implementations against the queue against boost’s SPSC queue that uses atomic under the hood as well (boost::lockfree::spsc_queue). Despite the queues using the same lockfree mechanism, the boost spsc queue significantly outperforms my implementation of the SPSC.
In part 2, I will discuss how the SPSC queue can be further optimized by leveraging memory barriers in std::atomic, and do some further optimizations. Spoiler alert: In one of my previous posts, I briefly discussed cache line false sharing (here) — we’ll see it in practice in part 2!