
SPSC Queue Part 2: Going Atomic
Optimizing lockfree single producer, single consumer (SPSC) queue

This post builds upon my previous article, where I implemented a bounded single-producer, single-consumer (SPSC) bounded queue using a combination of mutex and atomic operations. As observed in the article, the lock-free implementation leveraging std::atomic significantly outperformed the mutex-based version. However, boost::lockfree::spsc_queue proved to be more than five times faster than my implementation. In this post, I will explore further optimizations for the lock-free SPSC queue and benchmark its performance against Boost’s implementation. Before diving in, let’s briefly revisit the std::atomic based implementation —
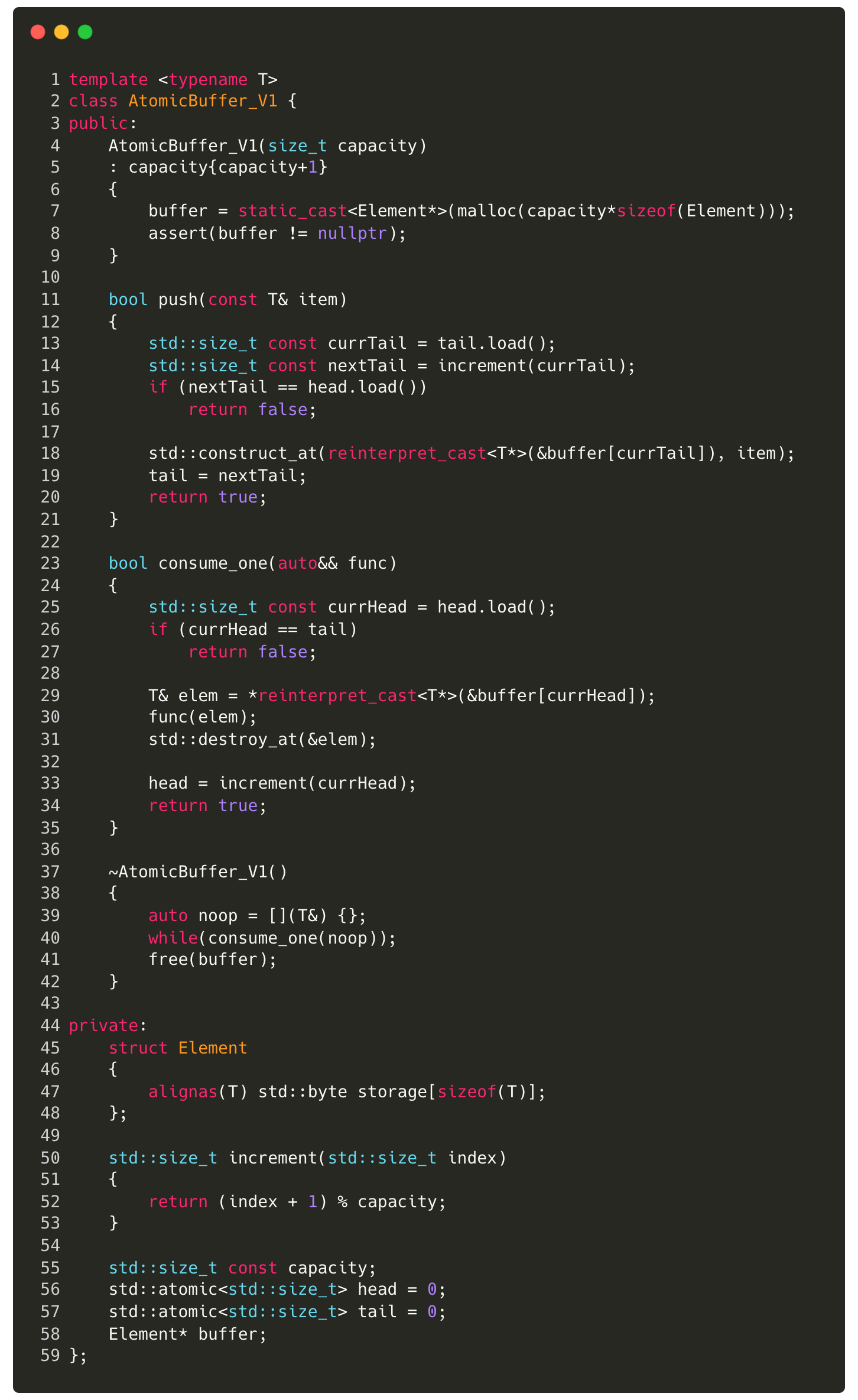
In our atomic buffer, we use atomic booleans to synchronize between the producer and consumer while tracking the correct position in the buffer. The actual read and write operations on the buffer’s memory during element construction and destruction can occur concurrently. This is a crucial insight — atomics ensure access to the correct memory location, while the data itself can be read or written concurrently.
Instruction Execution Order in CPU
In modern systems, the CPU does not always execute instructions sequentially. To maximize efficiency and instructions per cycle (IPC), it may reorder instructions dynamically — a technique known as out-of-order execution. In the previous code, notice that on line 19, the element's construction is independent of the update to the tail on line 20. Intuitively, one would expect these instructions to execute in sequence:
// producer thread
[line 19] 1. Write to memory buffer[tail]
[line 20] 2. Update (mem write) tail to tail + 1
// consumer thread
[line 29] 1. Read from memory buffer[head]However, in reality, the CPU may reorder these instructions. Let’s look at the consequences of this reordering. Assume the queue is initially empty, with head = tail = 0.
// producer thread after reordering
1. Update (mem write) tail (=0) to 1
2. Write to memory buffer[0]
// consumer thread
1. Read from memory buffer[0]This seemingly harmless reordering of two independent instructions can introduce incorrect behavior. Consider the following execution sequence:
Thread 1 (producer): Update tail to 1
Thread 2 (consumer): Read buffer[0]
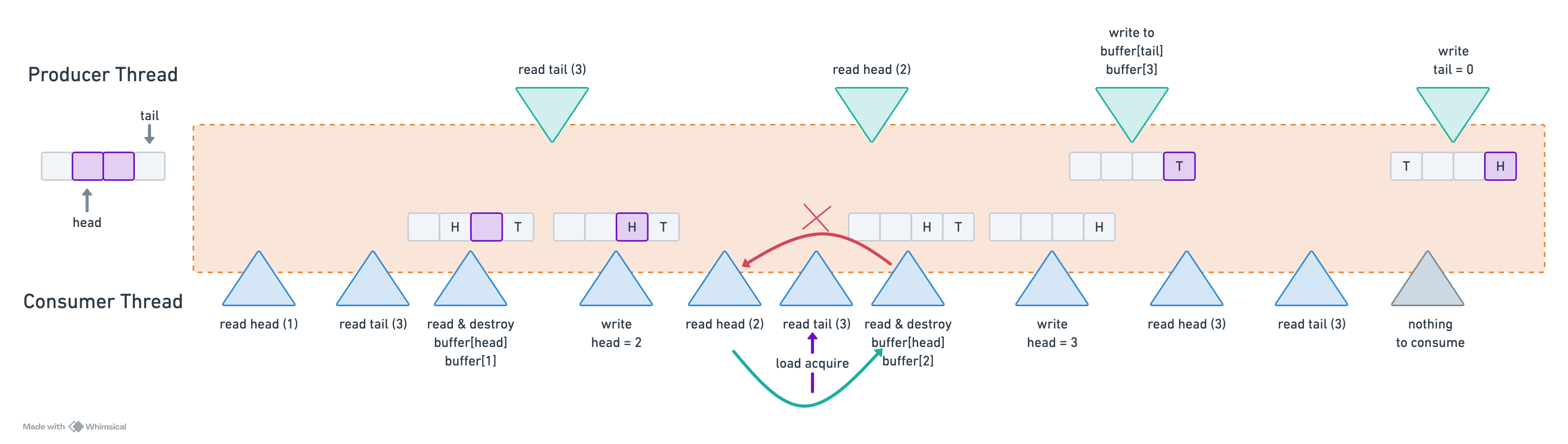
Thread 1 (producer): Write buffer[0]In this scenario, consumer thread attempts to access buffer[0] before producer thread has finished writing the element. A classic recipe for disaster! Below is a visual representation of the issue: the queue initially contains two elements, with head = 1 and tail = 3. The consumer operates significantly faster than the producer. While the producer is in the process of adding a new element, the consumer quickly consumes the existing elements.
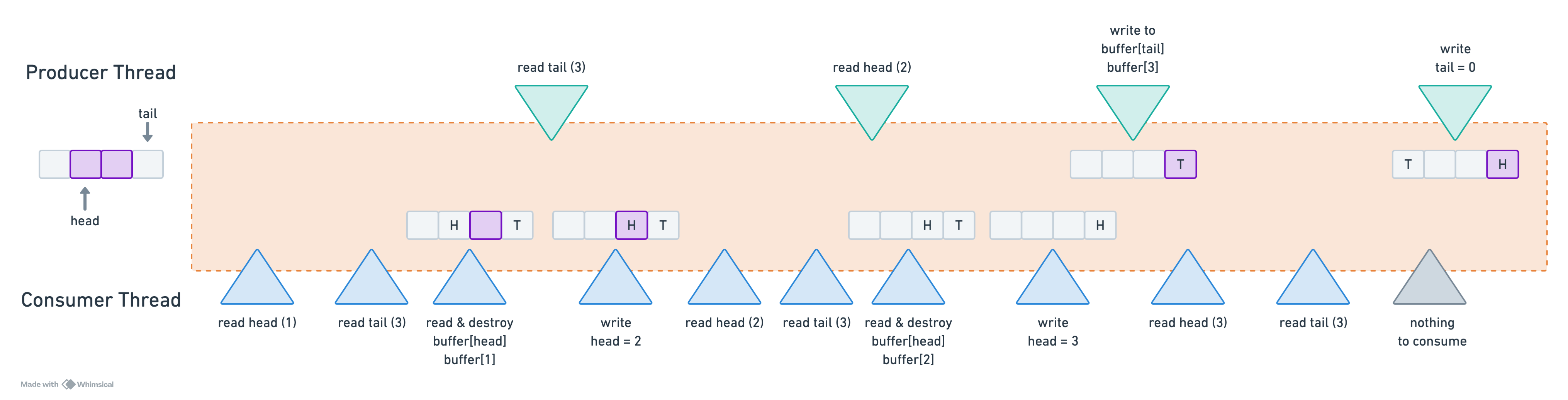
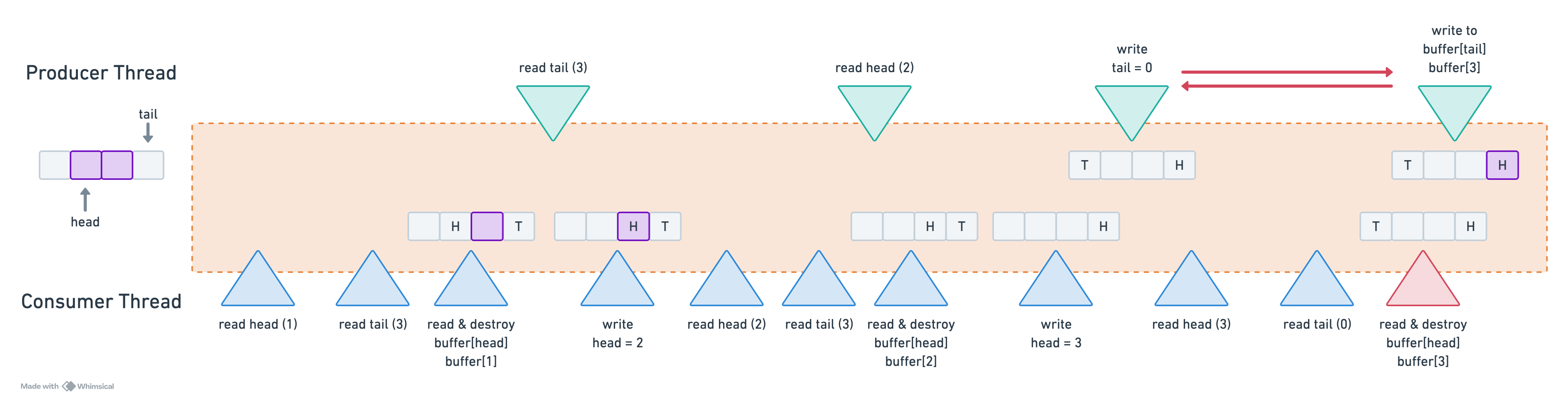
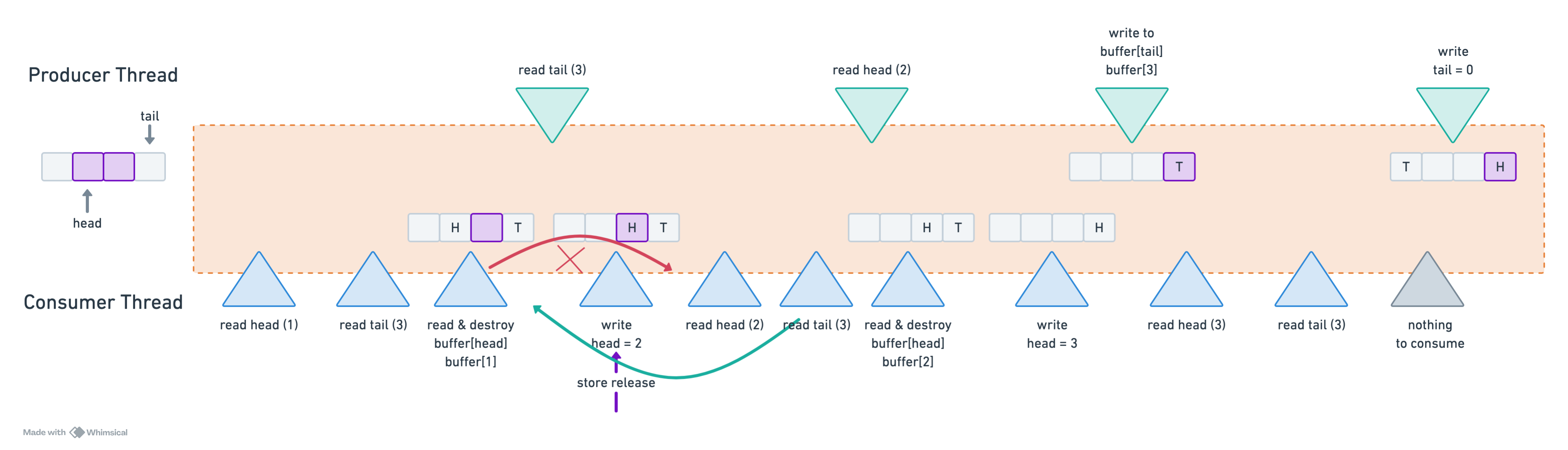
Under correct instruction ordering, the behavior remains well-defined— consume_one returns false when no elements are available. However, when reordering occurs, consume_one may attempt to consume an element from memory before it has been constructed, leading to undefined behavior.
Fortunately, the default load() and store() operations ensure that this reordering does not occur. This behavior is governed by memory ordering, which dictates how memory accesses surrounding an atomic operation are sequenced. As we will uncover, memory ordering has a significant impact on the performance.
Memory ordering in atomic
In the implementation above, we have established that, despite being independent operations, the write to the tail (producer thread) and the write to the head (consumer thread) must occur after accessing the memory for the construction (or destruction) of an element. This necessitates synchronization between the threads to ensure correctness.
What about the reads?
The producer thread reads both the tail and head. However, only the producer updates tail. When push() reads the tail, it is guaranteed that buffer[tail] is in a consistent state because only the producer writes to tail. Hence, no synchronization is required when for reading the tail in push().
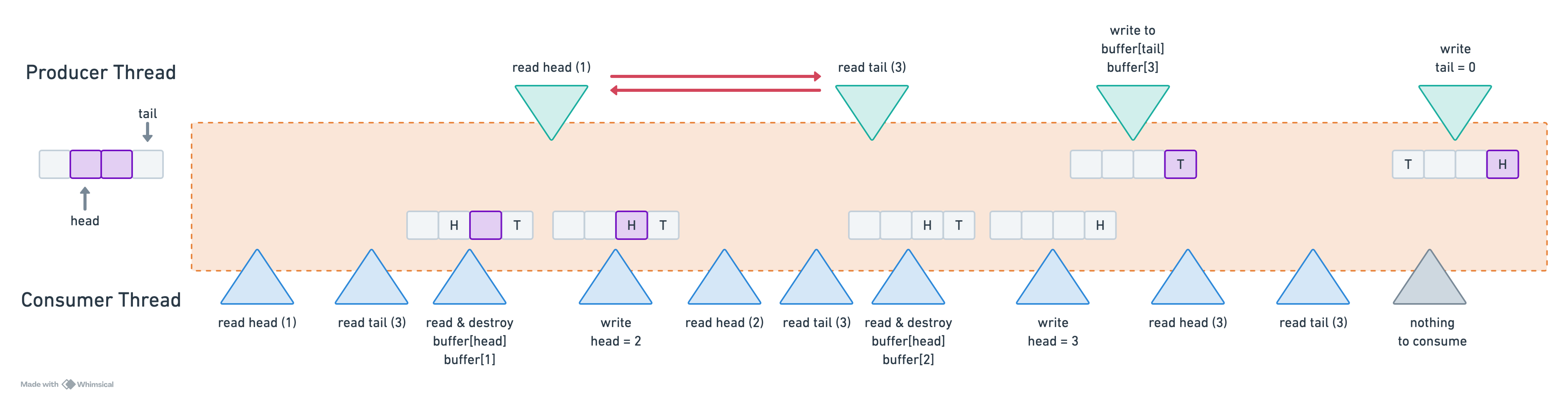
On the other hand, the consumer thread writes to head, while the producer reads it. This introduces a synchronization requirement: when the producer reads head, we must ensure that the consumer has already updated the corresponding memory. This means that synchronization is necessary between:
The write to head (by the consumer) and its read by the producer
The write to tail (by the producer) and its read by the consumer
We can specify memory ordering in load and store operations to either relax or enforce these synchronization constraints. Let’s have a look at some common orderings and how they impact performance and correctness.
Relaxed
Relaxed ordering only ensures the atomicity of the read/write to the atomic variable. There are no synchronization or ordering constraints imposed on other reads or writes. In case of relaxed load and store, the CPU would be allowed to reorder the operations above. The key advantage of relaxed ordering is its speed. Since the CPU is not bound by any ordering constraints, it can schedule instructions more efficiently. In some cases, atomicity is sufficient, and we don’t require synchronization between threads — relaxed ordering should be used there.
Optimization 1: Using relaxed ordering for some reads
bool push(const T& item)
{
std::size_t const currTail = tail.load(std::memory_order_relaxed);
...
}
bool consume_one(auto&& func)
{
std::size_t const currHead = head.load(std::memory_order_relaxed);
...
}Acquire
A load operation with acquire ordering ensures that no reads or writes in the current thread can be reordered before this load. That is, any read or write (atomic or non-atomic) that comes after the atomic load operation cannot be reordered before that. All writes in other threads that release the same atomic variable are visible in the current thread.
Release
A store operation with release ordering ensures that no reads or writes in the current thread can be reordered after this store. That is, any read or write (atomic or non-atomic) that comes before the atomic store operation cannot be reordered after that. All writes in the current thread are visible in other threads that acquire the same atomic variable.
Sequentially Consistent
A load operation with this memory order performs an acquire operation, a store performs a release operation. Additionally, a single total order exists in which all threads observe all modifications in the same order.
The details of total ordering are out of the scope of this article (I recommend watching Herb Sutter’s atomic weapons talk). For our purposes, the important distinction between acquire/release and sequentially consistent is that an acquire load synchronizes only with a release store on the same atomic variable but doesn't globally order unrelated atomic operations. Sequentially consistent ordering synchronizes amongst different atomic variables which makes it less efficient than acquire/release (see example in CppReference).
Optimization 2: Using release/acquire ordering
If an atomic store in thread A is tagged memory_order_release, an atomic load in thread B from the same variable is tagged memory_order_acquire, and the load in thread B reads a value written by the store in thread A, then the store in thread A synchronizes-with the load in thread B.
Consider the following example, where the producer writes data to a buffer and then sets a produced boolean to true. The consumer uses this boolean to synchronize access to the buffer. Instead of relying on the default sequentially consistent ordering, we use release/acquire ordering to optimize performance while maintaining correctness.
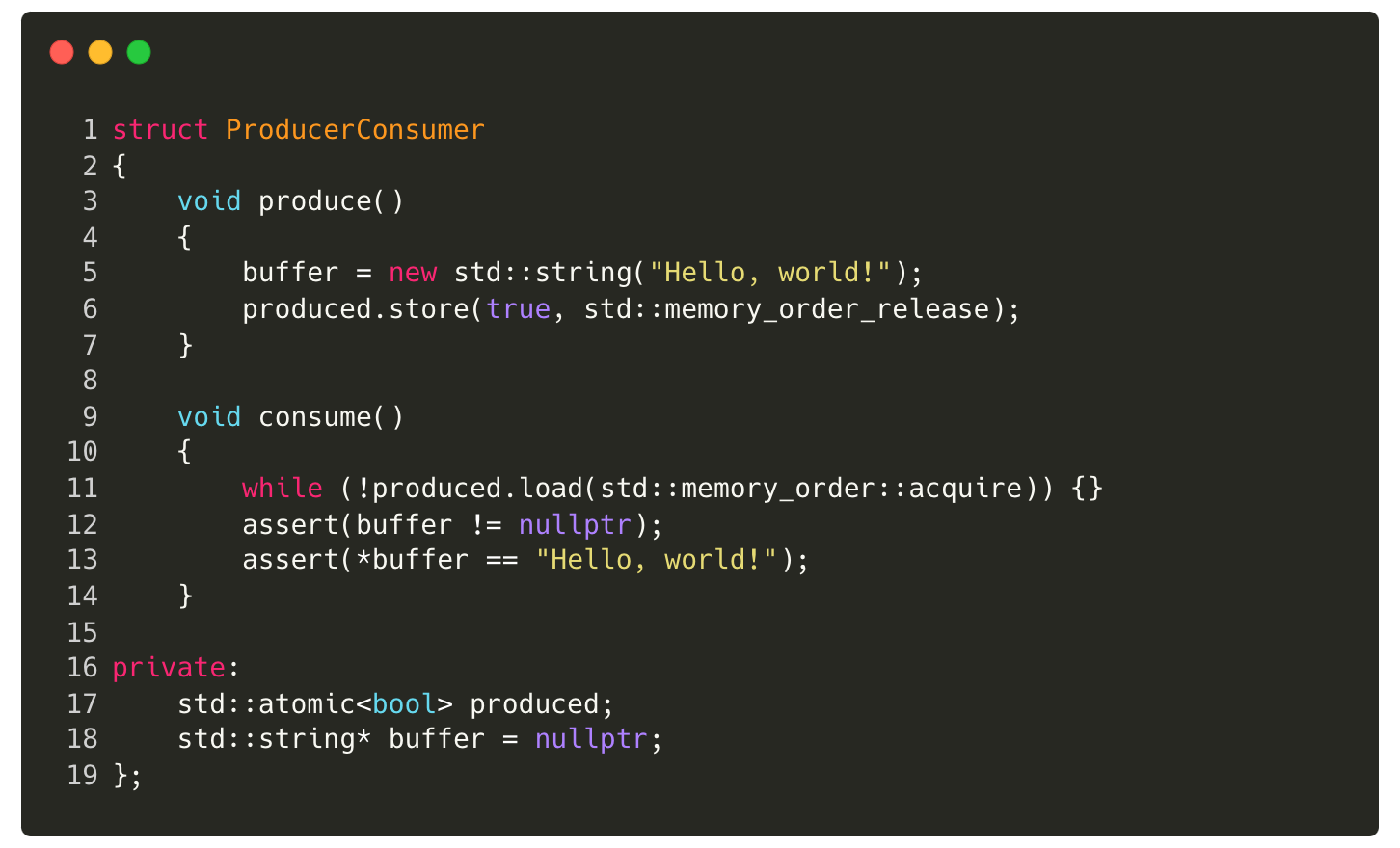
When the producer stores true into produced (line 6), using release ordering, it guarantees that all prior writes — specifically, the write to the buffer — are visible to other threads before produced is set.
When the consumer loads the value of produced using acquire ordering, it ensures that all writes before the producer set produced = true are now visible to the consumer. This means that when the consumer reads from the buffer, it is guaranteed to see the correct, fully written value.
Release/acquire ordering ensures that the consumer observes the correct ordering of operations without enforcing stricter constraints than necessary, making it more efficient than sequentially consistent ordering while still ensuring correctness.
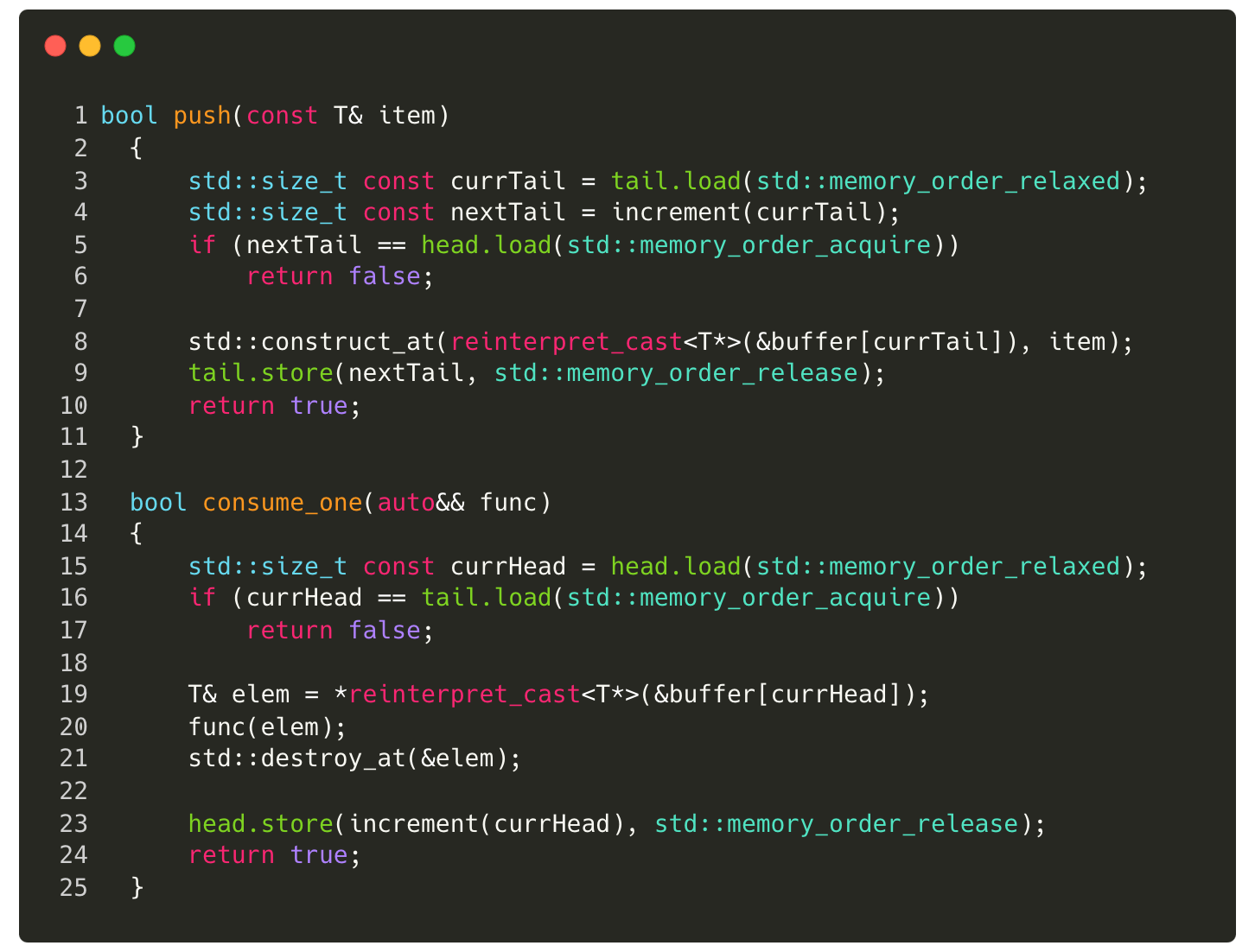
Below implementation of the atomic queue push and consume_one uses release/acquire ordering.
Profiling Atomic Queue v2
I profiled the queue using the same setup described in the previous article. The queue is now two times faster than the original atomic implementation! As evident, the memory ordering used significantly impacts performance.
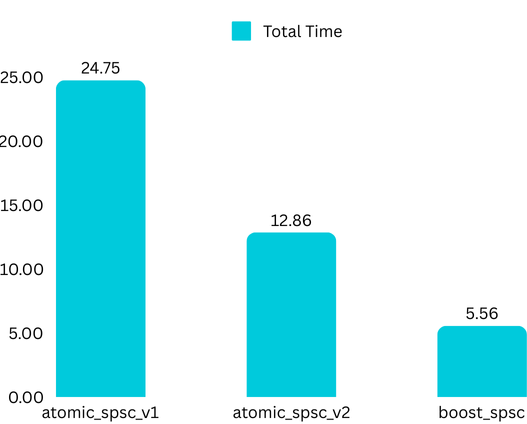
Although the performance has improved significantly, Boost’s SPSC queue still outperforms my implementation by a noticeable margin. Given the complexity of memory ordering, I will defer further optimizations to the next article. For the curious reader, I highly recommend the following resources:
The complete code can be found of GitHub.
Great Stuff. What about part 3 ? Can't wait :)
Excellent post! I always wanted to understand memory ordering, I am going over this post slowly word by word, code by code. Thank you for writing and posting 🙏